接續前一篇,接下來就是拿著前一篇的總頁數,繼續往下處理每個頁面的議題列表.
迴圈開始
#根據頁數執行迴圈
for (i in 1:totalpage){
url的頁碼,隨著迴圈數進行翻頁
比照前篇,準備所需資料的xpath,開始爬找.
#準備處理列表頁網址
url <- paste0(base.url,i)
doc <- read_html(url)
doc1<-xml_find_all(doc, "//*[@id='searchResult']/div/div/h4/a")
doc2<-xml_find_all(doc, "//*[@id='searchResult']/div/div/div/ul[2]/li")
比照所需要搜集的資料記錄,對應到xpath,一樣帶入程式中,取出資料.
這裡要注意的是date時間的xpath跟另兩組不同,記得要分開處理.
各自取出後,按data.frame物件收留.
簡單的判定,確認dfl這個物件在第一次被執行時,進行初始指定.
之後的每次,因資料欄位數相同,用函數rbind(),套句大家比較熟的說法,“插入一列”.
頁碼也一併置入.
#[解析]根據規則得出所需的資料
title<-xml_attr(doc1,"title")
href<-paste0(web.url,xml_attr(doc1, "href")) #Get tag href
date<-xml_text(doc2,"date")
if (i==1){
dfl<-data.frame(title,href,page=i,date)
}else{
dfl <- rbind(dfl, data.frame(title,href,page=i,date))
}
重要步驟:每次用runif()函數,發出1個2到8之間的亂數,當作系統暫停Sys.sleep()的秒數.(S大寫)
下方的右大括號,表示迴圈結束
Sys.sleep(runif(1,2,8))
}
迴圈結束後,代表所有的資料應該都已處理完畢.
此時,因需要一序號,當作一Key值.
這部分就引用函數rep(),跑一序列欄位出來.
再用所謂“插入一欄”cbind()函數處理.
#加入序號併入dfl
id=rep(1:nrow(dfl))
dfl=cbind(id,dfl)
#檢查一下資料
View(dfl)
檢視結果如下:共計搜集了500多筆議題紀錄.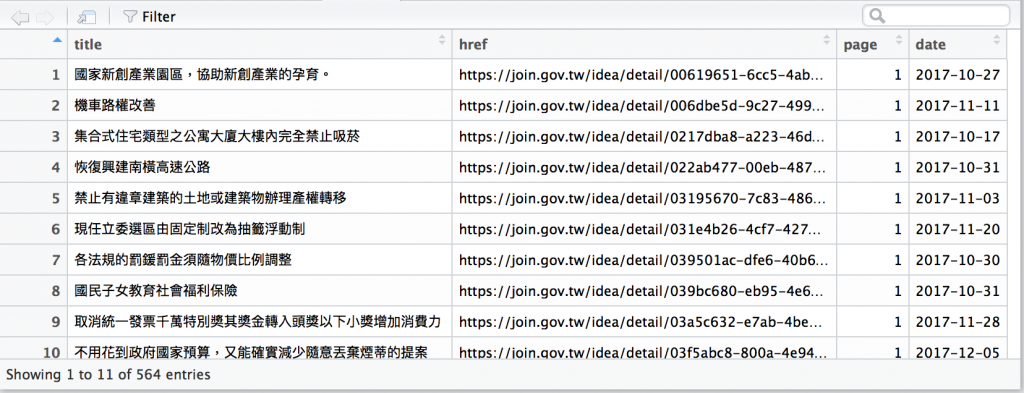
最後,可選擇將本次結果,輸出成為csv,作為資料來源或是傳遞資料之用.
存檔路徑,結合了上一篇工作檔路徑,並自行進行命名.
# write your table to file
write.csv(dfl,file=paste0(wdpath,"/dscsv/pagelist.csv"),row.names=FALSE)
以上就幾段程式碼,對R語言進行爬蟲的演示.
Kimi 您好:
觀看您的爬蟲程式文章多日,您寫得很詳細,
但執行 dfl<-data.frame(title,href,page=i,date)
遇到下列錯誤
Error in data.frame(title, href, page = i, date) :
arguments imply differing number of rows: 0, 1, 20
gooole諸多文章未能解決,尚請不吝指導
Joe 筆


